单纯形算法?干啥用的?它可以用于求解多维线性规划问题。
在开始之前,我们先约定一些记号:
- $\max z$ 或 $\min z$,表示求函数 $z$ 的最大值或最小值。
- $s.t.$ (subject to),表示满足某些条件,受到某些约束。
线性规划
回忆一下高中数学里二元线性规划的题目:设变量 $x, y$ 满足几个不等式的约束条件,求 $z = ax + by$ 的最大值或最小值。一个解决此类问题比较常用的方法是图解法,也就是在平面直角坐标系中,画出不等式约束条件所代表的可行域,然后将 $z = ax + by$ 化为直线形式 $y = -\frac{a}{b}x + \frac{z}{b}$ ,在可行域内移动这条直线,使得截距 $\frac{z}{b}$ 取得最大值或最小值,从而最大化或最小化 $z$ 的取值。
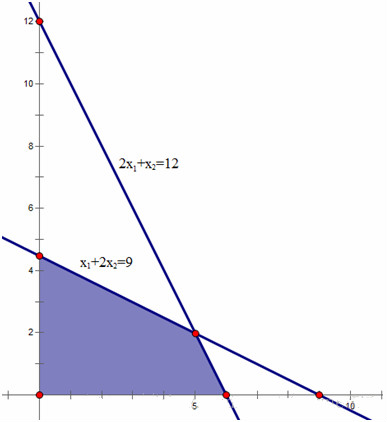
对于比较复杂的多元线性规划问题,图解法显然很难解决。此时我们可以使用单纯形算法来解决。
线性规划一般形式
对于线性规划问题,常以如下的一般形式给出:
- 目标函数 $\min z$ 或 $\max z$,其中 $z$ 等于 $m$ 个决策变量的加权和
- $m$ 个决策变量满足 $n$ 个方程约束或不等式约束
- 决策变量非负
$$\max z = c_1x_1 + c_2x_2 + … + c_mx_m$$ $$s.t. \begin{cases} a_{11}x_1 + a_{12}x_2 + … + a_{1m}x_m \le b_1 \\ a_{21}x_1 + a_{2 2}x_2 + … + a_{2m}x_m \le b_2 \\ … \\ a_{n1}x_1 + a_{n2}x_2 + … + a_{nm}x_m = b_n \\ x_1, x_2, …, x_m \ge 0 \end{cases}$$
将上面的模型简化:
$$\max z = \sum_{j=1}^{m} c_jx_j$$ $$s.t. \begin{cases}\sum_{i=1}^{m}a_{ij}x_j \le b_i (i \in 1, 2, …, n) \\ x_1, x_2, …, x_n \ge 0 \end{cases}$$
线性规划标准形式
为了使用单纯形算法来求解线性规划问题,需要先将线性规划模型化为标准形式。规定线性规划的标准形式满足:
- 目标函数为最大值:$\max z$
- 所有约束都为等式约束(方程约束)
- 决策变量非负
即:
$$\max z = \sum_{j=1}^{m} c_jx_j$$ $$s.t. \begin{cases}\sum_{i=1}^{m}a_{ij}x_j = b_i (i \in 1, 2, …, n) \\ x_1, x_2, …, x_n \ge 0 \end{cases}$$
可以证明:任意线性规划的一般形式,都可以通过对目标函数取负、添加松弛变量等操作,化成标准形式。
如何化成标准形式?
- 如果目标函数为最小值$\min z = \sum_{j=1}^{m} c_jx_j$,则可以通过对目标函数取负转化为求最大值;即将目标函数转化为:$\max -z = \sum_{j=1}^{m} c_j’x_j$, 其中 $c_j’ = -c_j$;
- 如果约束中存在小于等于不等式约束 $\sum_{j=1}^{m} a_{ij}x_j \le b_i$,则可以在等式左侧加上松弛变量 $x_{m+i}$,将其转化为等式约束:$\sum_{j=1}^{m} a_{ij}x_j + x_{m+i} = b_i$;
- 如果约束中存在大于等于不等式约束,同理可以在等式左侧减去松弛变量,将其转化为等式约束。
- 如果约束中存在无约束变量 $-\infty < x_j < \infty$,则可以将其表示为两个非负变量的差,即 $x_j = x_j^{‘} - x_j^{“}$.
举个栗子,对于以下线性规划形式:
$$\min -z = -x_1 - x_2$$ $$s.t. \begin{cases} 2x_1 + x_2 \le 12 \\ x_1 + 2x_2 \le 9 \\ x_1, x_2 \ge 0 \end{cases}$$
将其化为标准型:
$$\max z = x_1 + x_2 (+ 0x_3 + 0x_4)$$ $$s.t. \begin{cases} 2x_1 + x_2 + x_3 = 12 \\ x_1 + 2x_2 + x_4 = 9 \\ x_1, x_2, x_3, x_4 \ge 0 \end{cases}$$
可以看到,我们添加了两个松弛变量 $x_3, x_4$,使不等式约束化为了等式约束。
标准形式的矩阵表示
我们可以将上述线性规划的标准型,化成线性代数中的矩阵相乘形式以便后续的理解,如:
$$\max z = c^T X$$ $$ s.t. \begin{cases} AX = B \\ X \ge 0 \end{cases} $$
其中:
- $c$ 是目标函数中决策变量的加权系数列向量
- $X$ 是决策变量组成的列向量
- $A$ 是等式约束中的系数矩阵
- $B$ 则是等式右侧的常数矩阵
单纯形法
原理
首先,我们需要知道线性规划问题中的一个结论:线性规划问题的最优解,一定在可行域的顶点上。
单纯形法的原理是这样的:
单纯形法就是通过设置不同的基向量,经过矩阵的线性变换,求得基可行解(可行域顶点),并判断该解是否最优,否则继续设置另一组基向量,重复执行以上步骤,直到找到最优解。所以,单纯形法的求解过程是一个循环迭代的过程。
线性代数知识
线性无关:矢量空间中的一组向量 $\mathbf{a_1, a_2, …, a_n}$,如果任意一个向量 $\mathbf{a_i}$ 都不能被其它向量的线性组合表示,即 $\mathbf{a_i}$ 无法被表示为 $c_1\mathbf{a_1} + … c_{i-1}\mathbf{a_{i-1}} + c_{i+1}\mathbf{a_{i+1}} + … + c_{n}\mathbf{a_{n}}$ ($c_j$ 为常数,可取任意值),则称这组向量 $\mathbf{a_1, a_2, …, a_n}$ 线性无关。
基:向量空间 $\mathbf{V}$,若有一组线性无关的向量 ${\mathbf{a_1, a_2, …, a_n}} \subset \mathbf{V}$,使得对于 $\forall \mathbf{x} \in V$,向量 $\mathbf{x}$ 都可以被 ${\mathbf{a_1, a_2, …, a_n}}$ 线性表示,则称这组线性无关的向量为向量空间 $\mathbf{V}$ 的一组基。同一个向量空间的基可以是不唯一的。
基向量:向量空间基中的向量,即 $\mathbf{a_1, a_2…, a_n}$。
变换:
设在向量空间 $\mathbf{V}$ 中有两组基 $\mathbf{a_1, a_2, …, a_n}$ 及 $\mathbf{b_1, b_2, …, b_n}$,满足 $$\begin{cases} b_1 = p_{11}a_1 + p_{12}a_2 + … + p_{n1}a_n \\ b_2 = p_{21}a_1 + p_{22}a_2 + … + p_{n2}a_n \\ … \\ b_n = p_{n1}a_1 + p_{n2}a_2 + … + p_{nn}a_n \end{cases}$$
即:
$$(\mathbf{b_1, b_2, …, b_n}) = (\mathbf{a_1, a_2, …, a_n}) \cdot \mathbf{P}$$
这是一组基变换,也就是向量空间的一组基,可以通过乘上某一个变换矩阵,变成该向量空间的另一组基。
同理有坐标变换:设在向量空间有一向量 $\mathbf{x}$,以基 $\mathbf{a_1, a_2, …, a_n}$ 表示时的坐标为 $(x_1, x_2, .., x_n)^T$;以基 $\mathbf{b_1, b_2, …, b_n}$ 表示时的坐标为 $(x_1’, x_2’, …, x_n’)$;则有 $(x_1, x_2, …, x_n)^T$ 可以通过乘上某一个变换矩阵 $\mathbf{P}$ 转化为 $(x_1’, x_2’, …, x_n’)$.
从几何意义上来理解,对矩阵的旋转、缩放等等都是一种变换。
线性变换:满足线性性质的变换,线性性质指的是叠加性($T(\alpha_1 + \alpha_2) = T(\alpha_1) + T(\alpha_2)$)和齐次性($T(\lambda \alpha) = \lambda T(\alpha)$).
听起来似乎很复杂的样子,但是上面这些概念,只是对原理中的名词进行解释,可以暂时跳过。
具体步骤
STEP 1. 找到一组初始的可行解(可行基)
单纯形算法的第一步首先要找到一个初始的可行解,那么怎么找呢?以上述线性规划的标准型为例:
$$\max z = x_1 + x_2 (+ 0x_3 + 0x_4)$$ $$s.t. \begin{cases} 2x_1 + x_2 + x_3 = 12 \\ x_1 + 2x_2 + x_4 = 9 \\ x_1, x_2, x_3, x_4 \ge 0 \end{cases}$$
其中松弛变量为 $x_3, x_4$。我们可以将约束和目标函数写成矩阵表示的形式:
$$\max z = \left ( \begin{matrix}1 & 1 & 0 & 0\end{matrix} \right ) \left ( \begin{matrix} x_1 \\x_2 \\ x_3 \\ x_4 \end{matrix} \right ) $$ $$s.t. \left ( \begin{matrix} 2 & 1 & 1 & 0 \\1 & 2 & 0 & 1 \end{matrix} \right ) \left ( \begin{matrix} x_1 \\x_2 \\ x_3 \\x_4 \end{matrix} \right ) = \left ( \begin{matrix} 12 \\ 9 \end{matrix} \right )$$ $$\left ( \begin{matrix}x_1 \\ x_2 \\ x_3 \\ x_4\end{matrix} \right ) \ge 0$$
我们将约束方程写成以下形式:
$$\left ( \begin{matrix} 2 \\ 1 \end{matrix} \right ) x_1 + \left ( \begin{matrix} 1 \\ 2 \end{matrix} \right ) x_2 + \left ( \begin{matrix} 1 \\ 0 \end{matrix} \right ) x_3 + \left ( \begin{matrix} 0 \\ 1 \end{matrix} \right ) x_4 = \left ( \begin{matrix} 12 \\ 9 \end{matrix} \right )$$
$x_3, x_4$ 是我们引入的松弛变量。注意到它们对应的系数列向量总是线性无关的,所以对于这种形式我们可以直接取松弛变量作为可行基,即取 $x_3, x_4$ 为一组可行基。可以看出,如果令 $x_1 = 0, x_2 = 0, x_3 = 12, x_4 = 9$,则得到了一组可行解。 // What is this?
我们可以列出这样的一张表(称为单纯形表):
| $x_B$ | $b$ | $x_1$ | $x_2$ | $x_3$ | $x_4$ | $\theta$ |
|---|---|---|---|---|---|---|
| $x_3$ | 12 | 2 | 1 | 1 | 0 | 6 |
| $x_4$ | 9 | 1 | 2 | 0 | 1 | 9 |
| $z$ | 0 | 1 | 1 | 0 | 0 | - |
理解一下这张表格。这张表中,左侧的 $x_B$ 表示我们选取的基变量,$b$ 一列则是约束方程右侧的常数;表格中 $x_i$ 列中的内容则为约束方程中对应决策变量的系数;最下面一行 $z$ 表示目标函数中各项决策变量的权重系数以及当前的取值。因为我们选择的初始解为 $(0, 0, 12, 9)$,所以此时 $z=0$.
STEP 2. 寻找更优解
我们的目标函数是 $\max$ 形式,因此我们想要让目标函数尽可能地大。
在上一步当中,我们选择了松弛变量作为初始可行基,但是显然松弛变量并不会对目标函数 $z$ 产生任何的贡献,对目标函数产生贡献的变量是其它非基变量($x_1, x_2$);而增大 $x_1$ 或 $x_2$ 均可以让目标函数变大,那么我们便从剩余的非基变量 ${x_1, x_2}$ 中,选择若干个个非基变量来替换掉当前的基变量 ${ x_3, x_4 }$,使得目标函数增大同时满足约束。
假设我们想增加 $x_1$,让其成为基变量。因为要让 $z$ 尽可能大,所以 $x_1$ 也要尽可能地大,但是 $x_1$ 仍然受到约束,所以不能够无穷地增大。那么 $x_1$ 最大能增大到多少呢?为此我们考察含有 $x_1$ 的约束等式:
$$2x_1 + x_2 + x_3 = 12$$ $$x_1 + 2x_2 + x_4 = 9$$
为了让 $x_1$ 增大,必须要有其它的基变量减小,来维持等式成立。并且,为了使得 $x_1$ 尽可能大,其它变量就应该尽可能地为它“让路”——即为了让 $x_1$ 最大,则应该让 $x_3$ 或 $x_4$ 的系数减小到 0.
如果让 $x_3$ 的系数减小到 $0$,会让 $x_1$ 增加 $12 / 2 = 6$;让 $x_4$ 的系数减小到 $0$,会让 $x_1$ 增加 $9 / 1 = 9$ (这就是上面的单纯形表中最后一列 $\theta$ 的值). 我们发现让 $x_4$ 的系数减小到 $0$ 会比让 $x_3$ 的系数减小到 $0$ 时使得 $x_1$ 增加更多。但是,考虑到我们增大 $x_1$ 的同时要满足所有的约束条件,所以这里 $x_1$ 只能增大 $\min (6, 9) = 6$。所以我们只能让 $x_3$ 的系数减小到 $0$,此时 $x_3$ 被“换出”基变量成为非基变量,而$x_1$ 成为了基变量。
此时 $x_1$ 已经无法再增加了,因此我们要将约束中的 $x_1$ 的影响减到最小,只保留增大时用到的等式约束中的 $x_1$, 并把它单位化;然后从其余的等式约束中消去 $x_1$. 对增广矩阵进行初等行变换:
$$\left( \begin{matrix} 2 & 1 & 1 & 0 && 12 \\1 & 2 & 0 & 1 && 9 \end{matrix} \right ) \longrightarrow \left ( \begin{matrix}1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\1 & 2 & 0 & 1 && 9\end{matrix} \right ) \longrightarrow \left ( \begin{matrix} 1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\ 0 & \frac{3}{2} & -\frac{1}{2} & 1 && 3 \end{matrix} \right )$$
同样地,我们也要改变目标函数的形式。将目标函数写到增广矩阵的最后一行,然后对增广矩阵做初等行变换,减去变化的变量 $x_1$ 系数为 1 的那行:
$$\left ( \begin{matrix} 1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\ 0 & \frac{3}{2} & -\frac{1}{2} & 1 && 3 \\1 & 1 & 0 & 0 && z \end{matrix} \right ) \longrightarrow \left ( \begin{matrix}1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\ 0 & \frac{3}{2} & -\frac{1}{2} & 1 && 3 \\ 0 & \frac{1}{2} & -\frac{1}{2} & 0 && z-6 \end{matrix} \right )$$
也就是新的目标函数 $z=\frac{1}{2} x_2 - \frac{1}{2}x_3 + 6$,新的解向量为 $X = (6, 0, 0, 3)^T$.
经过上面的操作之后,我们得到了新的单纯形表:
| $x_B$ | $b$ | $x_1$ | $x_2$ | $x_3$ | $x_4$ |
|---|---|---|---|---|---|
| $x_1$ | 6 | 1 | $\frac{1}{2}$ | $\frac{1}{2}$ | 0 |
| $x_4$ | 3 | 0 | $\frac{3}{2}$ | $-\frac{1}{2}$ | 1 |
| $z$ | -6 | 0 | $\frac{1}{2}$ | -$\frac{1}{2}$ | 0 |
总结一下上面的操作:
- 找到某个非基变量 $x_i$,使得增大 $x_i$ 时能让目标函数增大
- 对于每一个约束等式,计算 $x_i$ 在满足当前式子的前提下,最大的变化值 $\theta_i = \frac{b_i}{c_i}$, $c_i$ 为当前约束等式中 $x_i$ 的系数
- 取所有约束等式中, $\theta_i$ 最小的一个约束等式,该等式对应的基变量 $x_B$ 作为换出变量
- 对于该约束等式,将换入的变量 $x_i$ 单位化,并对增广矩阵使用初等行变换,从其它的约束等式中消去 $x_i$
- 对目标函数进行变换,得到更优的解
STEP 3. 循环迭代上述过程,直到找到最优解
在上一步中,我们得到了新的解,但是它可能并不是最优解,所以我们继续迭代上面的过程,直到找到最优解为止。
回忆一下我们上面得到的单纯形表,目标函数变为了 $z = \frac{1}{2}x_2 - \frac{1}{2}x_3 + 6$,现在我们发现只有增大 $x_2$ 才能使得 $z$ 增大,所以我们这次选择 $x_2$ 作为换入变量,同时列出单纯形的表格:
| $x_B$ | $b$ | $x_1$ | $x_2$ | $x_3$ | $x_4$ | $\theta$ |
|---|---|---|---|---|---|---|
| $x_1$ | 6 | 1 | $\frac{1}{2}$ | $\frac{1}{2}$ | 0 | 12 |
| $x_4$ | 3 | 0 | $\frac{3}{2}$ | $-\frac{1}{2}$ | 1 | 2 |
| $z$ | -6 | 0 | $\frac{1}{2}$ | -$\frac{1}{2}$ | 0 | - |
仿照上一步的操作,我们应该选择 $\min { 12, 2 } = 2$ 列所对应的基变量 $x_4$ 作为换出变量。对上述矩阵做初等行变换:
$\left ( \begin{matrix} 1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\0 & \frac{3}{2} & -\frac{1}{2} & 1 && 3 \\0 & \frac{1}{2} & -\frac{1}{2} & 0 && -6 \end{matrix} \right ) \longrightarrow \left ( \begin{matrix} 1 & \frac{1}{2} & \frac{1}{2} & 0 && 6 \\0 & 1 & -\frac{1}{3} & \frac{2}{3} && 2 \\0 & \frac{1}{2} & -\frac{1}{2} & 0 && -6 \end{matrix} \right )$
$\longrightarrow \left ( \begin{matrix} 1 & 0 & \frac{2}{3} & -\frac{1}{3} && 5 \\0 & 1 & -\frac{1}{3} & \frac{2}{3} && 2 \\0 & 0 & -\frac{1}{3} & -\frac{1}{3} && -7 \end{matrix} \right )$
此时得到新的单纯形表:
| $x_B$ | $b$ | $x_1$ | $x_2$ | $x_3$ | $x_4$ |
|---|---|---|---|---|---|
| $x_1$ | 5 | 1 | 0 | $\frac{2}{3}$ | -$\frac{1}{3}$ |
| $x_2$ | 2 | 0 | 1 | -$\frac{1}{3}$ | $\frac{2}{3}$ |
| $z$ | -7 | 0 | 0 | -$\frac{1}{3}$ | $-\frac{1}{3}$ |
新的目标函数是:$z = -\frac{1}{3}x_3 - \frac{1}{3}x_4 + 7$,对应解向量 $X = (5, 2, 0, 0)$.
此时的目标函数中变量的系数都为负,无论增大 $x_3$ 或是 $x_4$,都不会使得目标函数的取值变得更大,所以我们的操作结束了,$z_{max} = 7$ 即为最优解。
总结
到此我们总结一下单纯形法求解线性规划问题的步骤:
- 对于一个线性规划模型的一般形式,通过目标函数取负、增加或改写松弛变量等方式,将线性规划模型标准形式化为具有 $m$ 个变量和 $n$ 个约束条件的形式。
- 找到一组 $n$ 个基变量(一般选取引入的松弛变量,要求这些基变量在系数矩阵中对应的系数列向量组线性无关),得到初始基和基础解系。
- 选取非基变量 $x_j$ 代替基变量 $x_k$,这一步会使得 $x_j$ 增大、$x_k$ 减小。考察目标函数 $\max z = \sum_{i=1}^{n} c_ix_i$,为了使得 $z$ 取到最大值,选出的“进基”变量 $x_j$ 的系数应满足 $c_j > 0$,才能满足 $x_j$ 增大时目标函数 $z$ 增大。如果这一步中有多个 $c_j > 0$,则选择 $c_j$ 最大的那一个变量。
- 选取被替代的基变量 $x_k$。首先对于每一个约束等式,计算 $\theta_i = \frac{b}{c_{ij}}$,选择 $\theta_i$ 最小的那一个等式对应的基变量作为“出基”变量。
- 进行初等行变换,得到新的约束增广矩阵和目标函数。
- 重复上述步骤,直到 $z$ 中所有变量的系数 $c_i \le 0$ 时,算法结束。
代码
模板:UOJ #179. 线性规划,这道题多少有点玄学……
#include <bits/stdc++.h>
using namespace std;
const int maxn = 25, maxm = 100050;
const double eps = 1e-8, inf = (double)(1ll << 60);
int n, m, t, id[maxn << 1]; // n: variables, m: constraint
double a[maxn][maxn], ans[maxn]; // a: coefficient matrix
template<class T> void read(T &x) {
T a = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
f = ch == '-' ? -1 : f, ch = getchar();
while (ch >= '0' && ch <= '9')
a = a * 10 + ch - '0', ch = getchar();
x = a * f;
}
void pivot(int l, int e) {
swap(id[n+l], id[e]);
double tmp = a[l][e];
a[l][e] = 1;
for (int j = 0; j <= n; j++)
a[l][j] /= tmp;
for (int i = 0; i <= m; i++)
if (i != l && abs(a[i][e]) > eps) {
tmp = a[i][e], a[i][e] = 0;
for (int j = 0; j <= n; j++)
a[i][j] -= a[l][j] * tmp;
}
}
bool init() {
while (1) {
int e = 0, l = 0;
for (int i = 1; i <= m; i++)
if (a[i][0] < -eps && (!l || (rand() & 1)))
l = i;
if (!l)
break;
for (int j = 1; j <= n; j++)
if (a[l][j] < -eps && (!e || (rand() & 1)))
e = j;
if (!e) {
printf("Infeasible\n"); // 不存在满足约束的解
return false;
}
pivot(l, e);
}
return true;
}
bool simplex() {
while (1) {
int l = 0, e = 0;
double minv = inf;
for (int j = 1; j <= n; j++)
if (a[0][j] > eps) {
e = j;
break;
}
if (!e)
break;
for (int i = 1; i <= m; i++)
if (a[i][e] > eps && a[i][0] / a[i][e] < minv)
minv = a[i][0] / a[i][e], l = i;
if (!l) {
printf("Unbounded\n"); // 任意解
return false;
}
pivot(l, e);
}
return true;
}
int main() {
srand(time(NULL));
read(n), read(m), read(t);
for (int i = 1; i <= n; i++)
read(a[0][i]);
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++)
read(a[i][j]);
read(a[i][0]);
}
for (int i = 1; i <= n; i++)
id[i] = i;
if (init() && simplex()) {
printf("%.8lf\n", -a[0][0]);
if (t) {
for (int i = 1; i <= m; i++)
ans[id[n + i]] = a[i][0];
for (int i = 1; i <= n; i++)
printf("%.8lf ", ans[i]);
}
}
return 0;
}
Ext: 对偶原理
假设有这样一个线性规划模型:
$$\max z = \sum_{j=1}^{m} c_jx_j$$
$$s.t. \begin{cases} \sum_{j=1}^m a_{ij}x_j \le b_i, i = 1…n \\ x_j \ge 0 \end{cases}$$
它的对偶问题是:
$$\min z = \sum_{j=1}^{n} b_ix_i$$ $$s.t. \begin{cases}\sum_{i=1}^{n}c_jix_i \ge c_i, i = 1…m \\ x_i \ge 0\end{cases}$$
对偶问题与原始问题之间存在着下列关系: - 目标函数对原始问题是极大化,对对偶问题则是极小化 - 原始问题目标函数中的收益系数是对偶问题约束不等式中的右端常数,而原始问题约束不等式中的右端常数则是对偶问题中目标函数的收益系数 - 原始问题和对偶问题的约束不等式的符号方向相反 - 原始问题约束不等式系数矩阵转置后即为对偶问题的约束不等式的系数矩阵 - 原始问题的约束方程数对应于对偶问题的变量数,而原始问题的变量数对应于对偶问题的约束方程数 - 对偶问题的对偶问题是原始问题,这一性质被称为原始和对偶问题的对称性